Alignment Techniques for Large Language Models
Date:
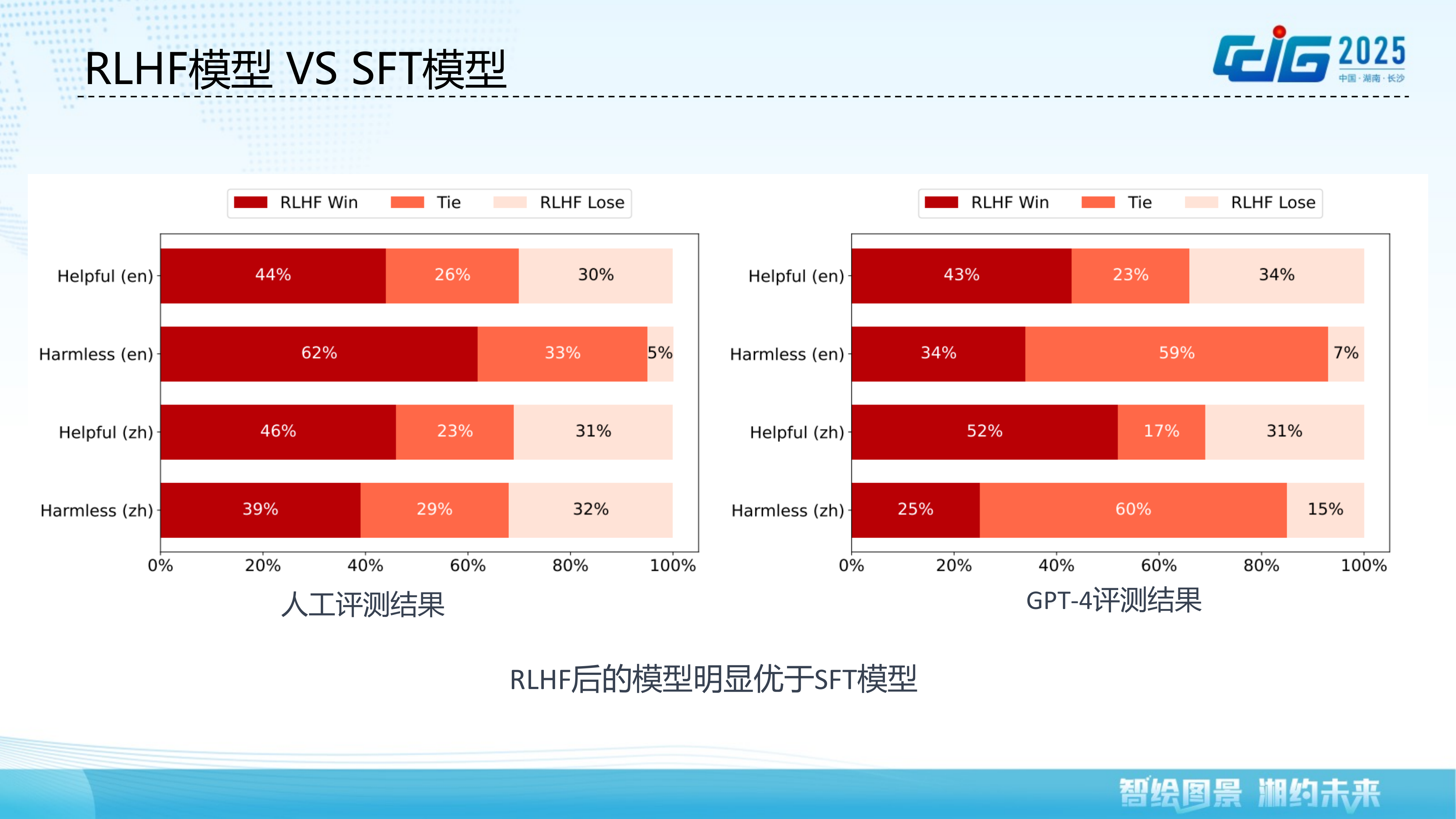
While large language models demonstrate remarkable capabilities, they also pose safety and ethical risks that necessitate alignment with human values. This talk provides a systematic overview of recent advances in LLM alignment techniques. We first motivate the need for alignment by examining safety and ethical challenges, along with the core alignment principles of helpfulness, honesty, and harmlessness. We then delve into human preference modeling, covering key issues such as reward model training, generalization, and online updating. Building on this foundation, we present RLHF-based alignment techniques including the PPO-MAX algorithm for stable training, Direct Preference Optimization (DPO), Linear Alignment for inference-time alignment, and multi-path feedback fusion methods. The talk also discusses post-alignment evaluation approaches for both safety/value alignment and capability alignment. Finally, we explore future directions including Self-Play multi-policy adversarial learning and reinforcement learning-centric reasoning models such as O1.