大语言模型对齐技术
Date:
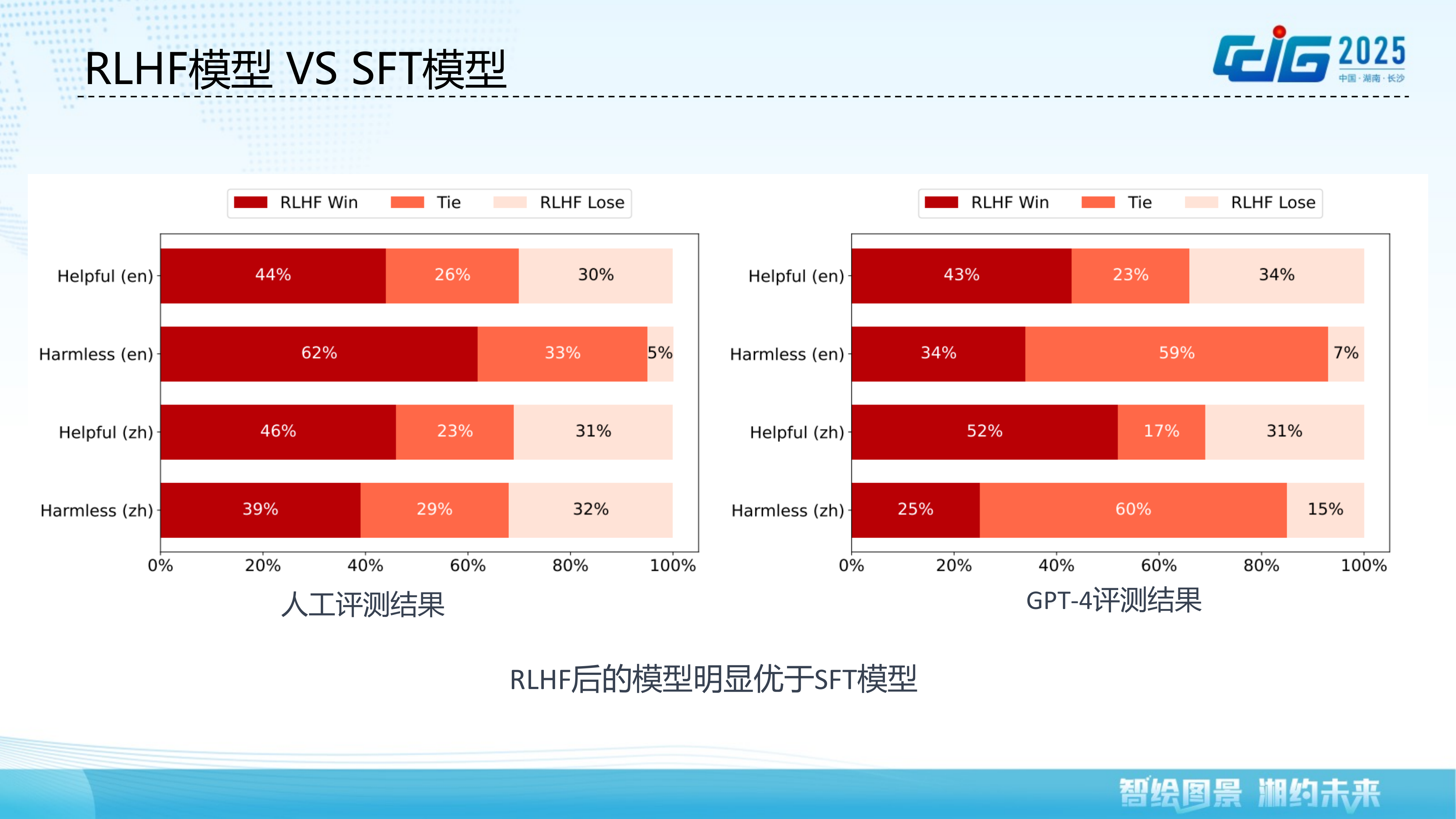
大语言模型在展现强大能力的同时,也存在安全与伦理风险,需要与人类价值观进行对齐。本报告系统介绍大语言模型对齐技术的最新进展。首先阐述对齐的必要性,分析大模型面临的安全伦理问题以及对齐的核心准则(有益性、诚实性、无害性)。随后深入介绍人类偏好建模方法,包括奖励模型的训练、泛化与在线更新等关键问题。在此基础上,重点讲解基于 RLHF 的对齐技术,涵盖 PPO-MAX 稳定训练算法、DPO 直接偏好优化、Linear Alignment 推理阶段对齐、以及多途径反馈融合等方法。报告还讨论了对齐后的模型评测方法,包括安全与价值观评测和能力对齐评测。最后展望对齐技术的未来方向,包括 Self-Play 多策略对抗学习以及以强化学习为核心的推理模型(如 O1)。